A few days ago, the World Meteorological Organization (WMO) issued a press release announcing that globally averaged Carbon Dioxide (CO2) levels in the atmosphere have reached the symbolic and significant milestone of 400 parts per million (ppm) for the entire year. The UN agency made a bold prediction, painted a bleak picture if the trend continues, and declared that this marks the start of a new era of climate reality.
From the WMO press release:
“CO2 levels had previously reached the 400 ppm barrier for certain months of the year and in certain locations but never before on a global average basis for the entire year. The longest-established greenhouse gas monitoring station at Mauna Loa, Hawaii, predicts that CO2 concentrations will stay above 400 ppm for the whole of 2016 and not dip below that level for many generations.”
Next Generation Science Standards & Enabling Students to Explore CO2 Data
Did you know that the historical Atmospheric Carbon Dioxide data from the Mauna Loa Observatory is in the Tuva Datasets Library?
Tuva’s Atmospheric Carbon Dioxide (1958-2015) (Tuva Premium subscribers only) dataset enables your students to wear the hat of a meteorologist. Students can easily explore, visualize, analyze, and model the atmospheric Carbon Dioxide data from the Mauna Loa observatory, just like the meteorologists at WMO.
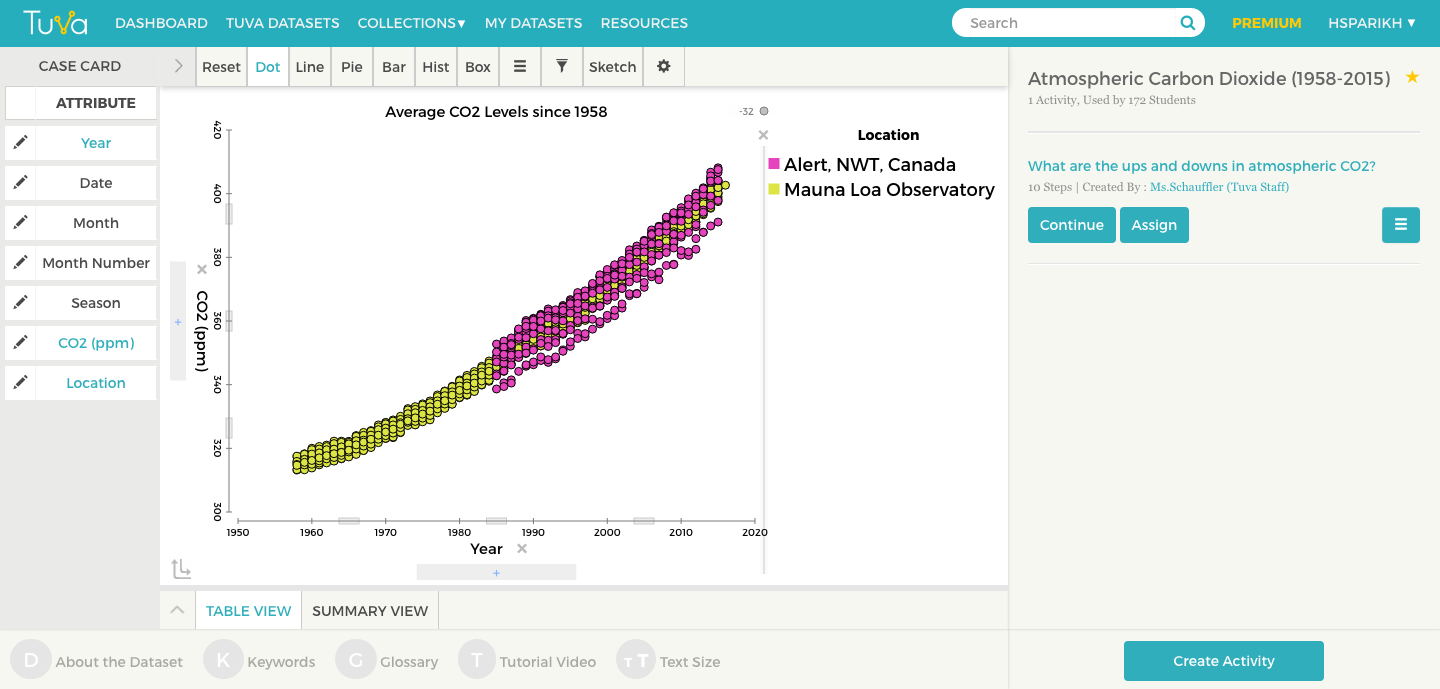
They can explore critical questions such as:
a. How has the globally averaged CO2 levels increased over the last 50 years?
b. When did the average CO2 level first past the 400ppm threshold?
c. How does the average CO2 levels vary by seasons, and why?
d. If this increasing trend continues, what will be the global average CO2 levels in 2050?
Cultivating students’ scientific habits of mind, building their capability to engage in scientific inquiry, and engaging them in practices that reflect those of scientists, researchers, and engineers is one of the primary goals of the Next Generation Science Standards.
At this watershed moment in climate science and human history, Tuva enables you to realize this vision with your students.